发布时间:2025-02-11 19:28:10 点击量:
HASH GAME - Online Skill Game GET 300
添加一个元素的时候,首先计算元素key的hash值,确定插入数组中的位置。如果当前位置下没有重复数据,则直接添加到当前位置。当遇到冲突的时候,添加到同一个hash值的元素后面,行成一个链表。这个链表的特点是同一个链表上的Hash值相同。java的数据结构HashMap使用的就是这种方法来处理冲突,JDK1.8中,针对链表上的数据超过8条的时候,使用了红黑树进行优化。由于篇幅原因,这里不深入讨论相关数据结构,有兴趣的同学可以参考这篇文章:
开放地址法是指大小为 M 的数组保存 N 个键值对,其中 M>
N。我们需要依靠数组中的空位解决碰撞冲突。基于这种策略的所有方法被统称为“开放地址”哈希表。线性探测法,就是比较常用的一种“开放地址”哈希表的一种实现方式。线性探测法的核心思想是当冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。简单来说就是:一旦发生冲突,就去寻找下 一个空的散列表地址,只要散列表足够大,空的散列地址总能找到。
对于开放寻址冲突解决方法,除了线性探测方法之外,还有另外两种比较经典的探测方法,二次探测(Quadratic probing)和双重散列(Double hashing)。但是不管采用哪种探测方法,当散列表中空闲位置不多的时候,散列冲突的概率就会大大提高。为了尽可能保证散列表的操作效率,一般情况下,我们会尽可能保证散列表中有一定比例的空闲槽位。我们用装载因子(load factor)来表示空位的多少。
在数据校验方面的另一个应用场景就是版权的保护或者违禁信息的打击,比如某个小视频,第一个用户上传的时候,我们认为是版权所有者,计算一个hash值存下来。当第二个用户上传的时候,同样计算hash值,如果hash值一样的话,就算同一个文件。这种方案其实也给用户传播违禁文件提高了一些门槛,不是简单的换一个名字或者改一下后缀名就可以躲避掉打击了。(当然这种方式也是可以绕过的,图片的你随便改一下颜色,视频去掉一帧就又是完全不同的hash值了。注意:我没有教你变坏,我只是和你在讨论这个技术。。。)另外我们在社区里,也会遇到玩家重复上传同一张图片或者视频的情况,使用这种校验的方式,可以有效减少cos服务的存储空间。
使用过bt的同学都有经验,在p2p网络中会把一个大文件拆分成很多小的数据各自传输。这样的好处是如果某个小的数据块在传输过程中损坏了,只要重新下载这个块就好。为了确保每一个小的数据块都是发布者自己传输的,我们可以对每一个小的数据块都进行一个hash的计算,维护一个hash List,在收到所有数据以后,我们对于这个hash List里的每一块进行遍历比对。这里有一个优化点是如果文件分块特别多的时候,如果遍历对比就会效率比较低。可以把所有分块的hash值组合成一个大的字符串,对于这个字符串再做一次Hash运算,得到最终的hash(Root hash)。在实际的校验中,我们只需要拿到了正确的Root hash,即可校验Hash List,也就可以校验每一个数据块了。
下面我们来看一点复杂的问题,假设我们活动初始分表了10张,运营一段时间以后发现需要10张不够,需要改到100张。这个时候我们如果直接扩容的话,那么所有的数据都需要重新计算Hash值,大量的数据都需要进行迁移。如果更新的是缓存的逻辑,则会导致大量缓存失效,发生雪崩效应,导致数据库异常。造成这种问题的原因是hash算法本身的缘故,只要是取模算法进行处理,则无法避免这种情况。针对这种问题,我们就需要利用一致性hash进行相应的处理了。
一致性hash的基本原理是将输入的值hash后,对结果的hash值进行2^32取模,这里和普通的hash取模算法不一样的点是在一致性hash算法里将取模的结果映射到一个环上。将缓存服务器与被缓存对象都映射到hash环上以后,从被缓存对象的位置出发,沿顺时针方向遇到的第一个服务器,就是当前对象将要缓存于的服务器,由于被缓存对象与服务器hash后的值是固定的,所以,在服务器不变的情况下,一个openid必定会被缓存到固定的服务器上,那么,当下次想要访问这个用户的数据时,只要再次使用相同的算法进行计算,即可算出这个用户的数据被缓存在哪个服务器上,直接去对应的服务器查找对应的数据即可。这里的逻辑其实和直接取模的是一样的。如下图所示:
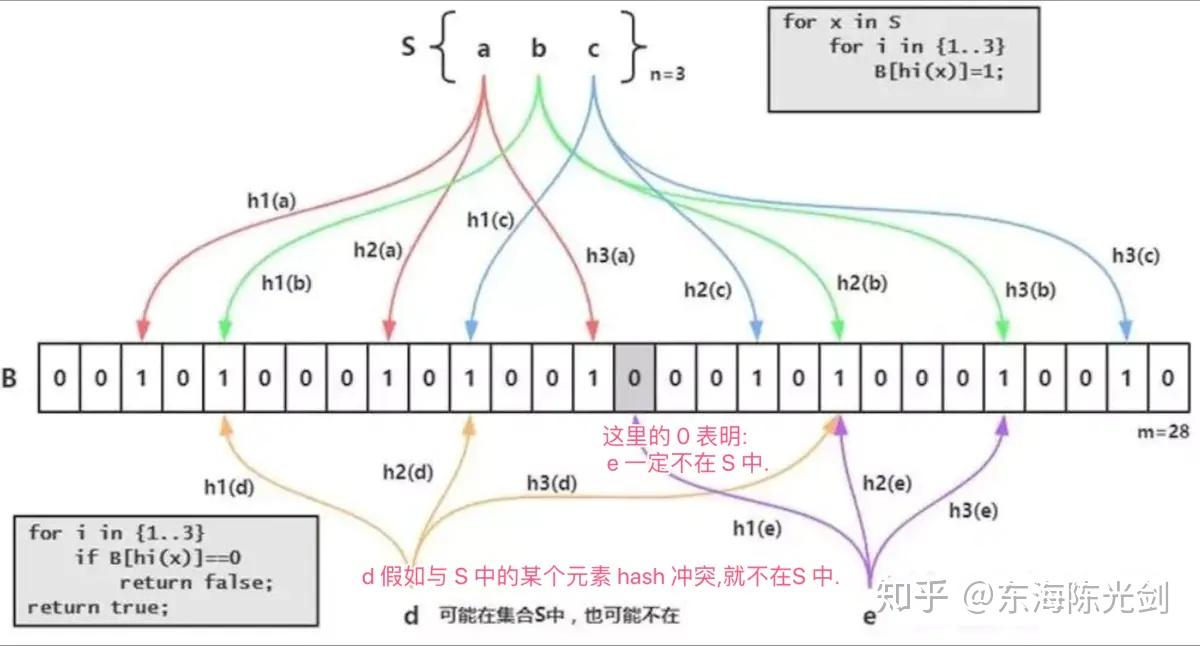
布隆过滤器其实是基于bitmap的一种应用,在1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数,用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难,主要用于大数据去重、垃圾邮件过滤和爬虫url记录中。核心思路是使用一个bit来存储多个元素,通过这样的方式来减少内存的消耗。通过多个hash函数,将每个数据都算出多个值,存放在bitmap中对应的位置上。






